Типичные ошибки в работе проверок
На этой странице описаны часто встречающиеся ошибки в работе DQ проверок.
Где доступны логи DQ
Для удобства поиска по логам DQ мы рекомендуем настроить отправку логов в OpenSearch или ELK. Для этого см. инструкцию
| Интерфейс | Возможности |
|---|---|
| DQ UI на странице с Run. | Просмотр логов по каждому запуску (Run) в отдельности Фильтрация по уровню логирования (levelname) Поиск средствами браузера |
| OpenSearch или Kibana | Расширенные возможности поиска и фильтрации логов |
| Файлы с логами на DQ worker | Можно написать нам в чат поддержки, если вам нужны логи за более длительный период, чем они доступны в DQ UI или OBS |
Как работать с логами DQ в OpenSearch
-
Перейдите в OpenSearch UI
-
Выберите ваш индекс
-
Для поиска логов по вашим проверок нужно обязательно указать фильтр по run_id:
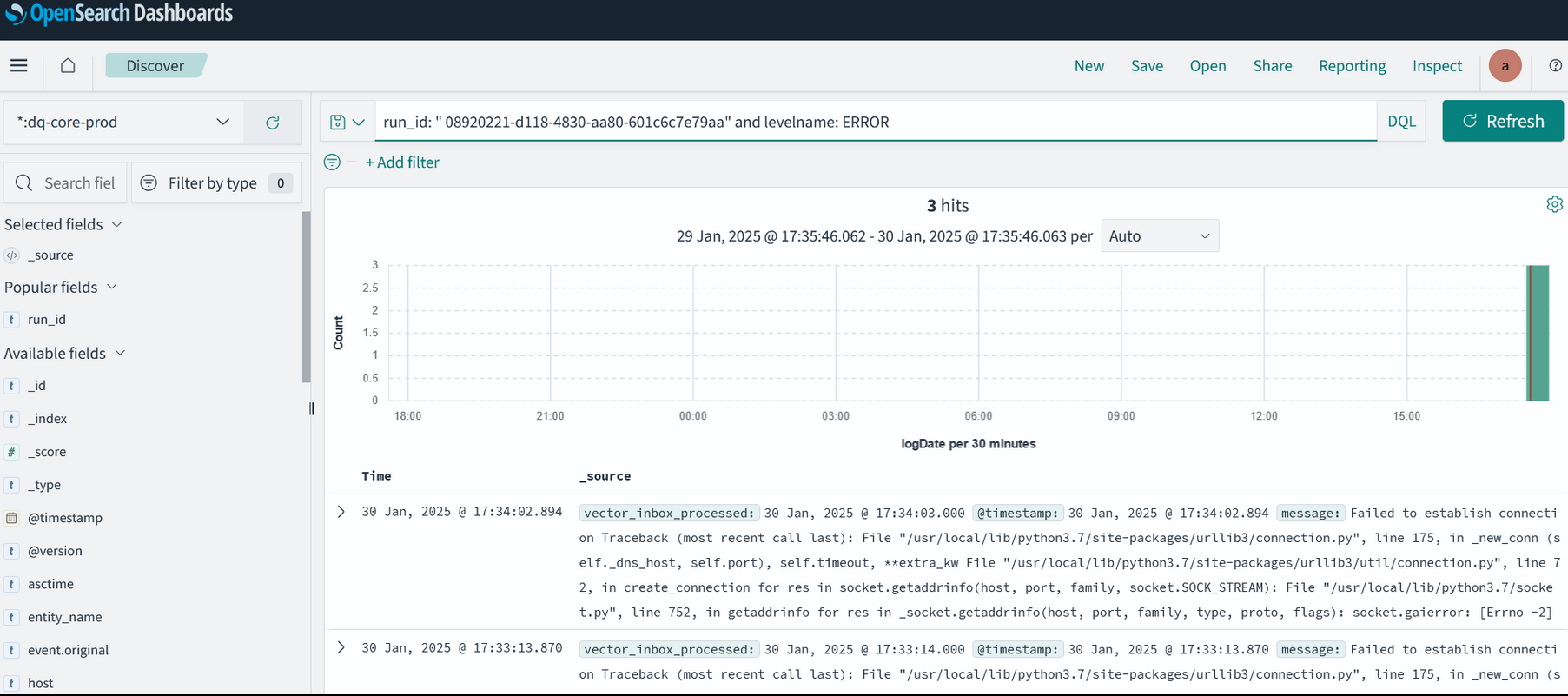
-
В списке Available Fields слева выберите поле message:
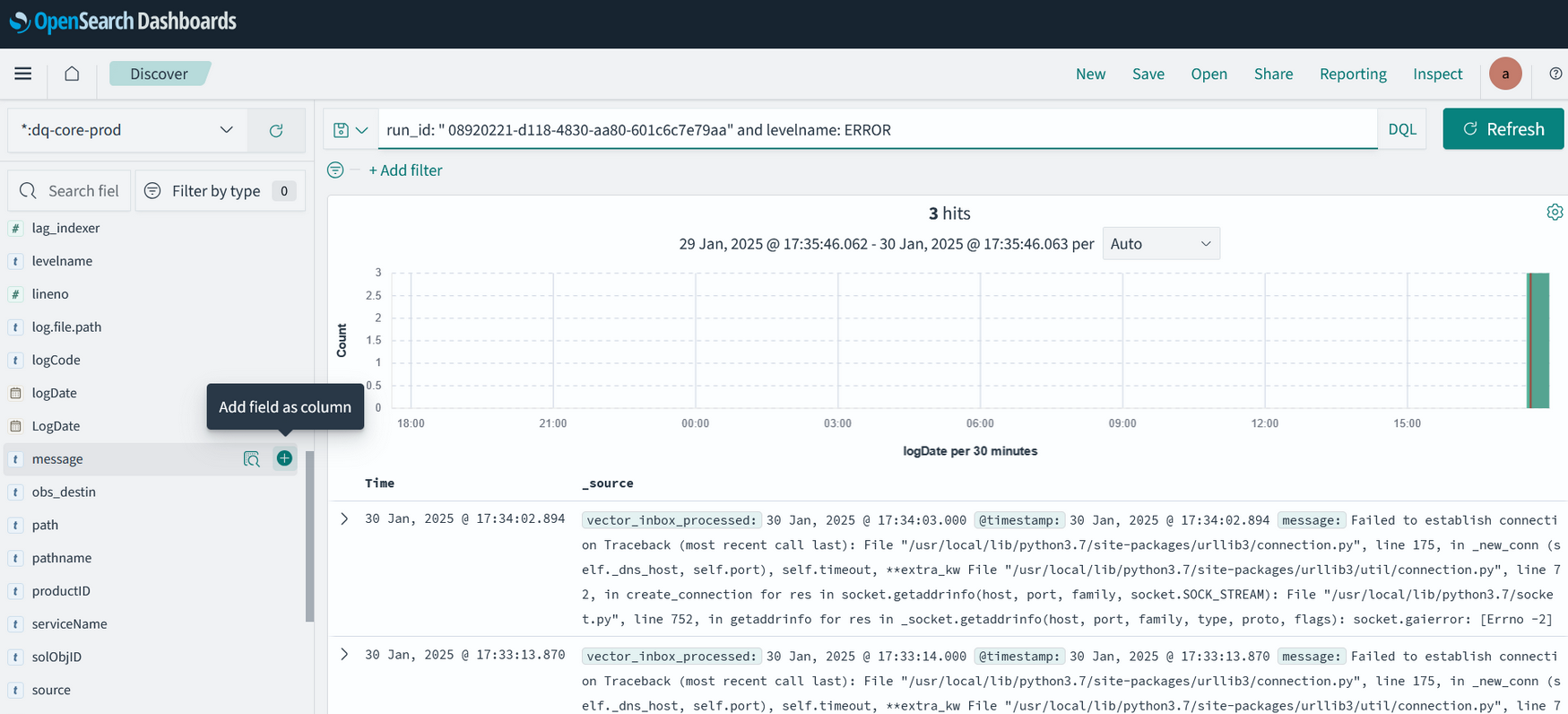
-
Теперь в интерфейсе OpenSearch отображается только сообщения от самого DQ - без дополнительных технических полей:
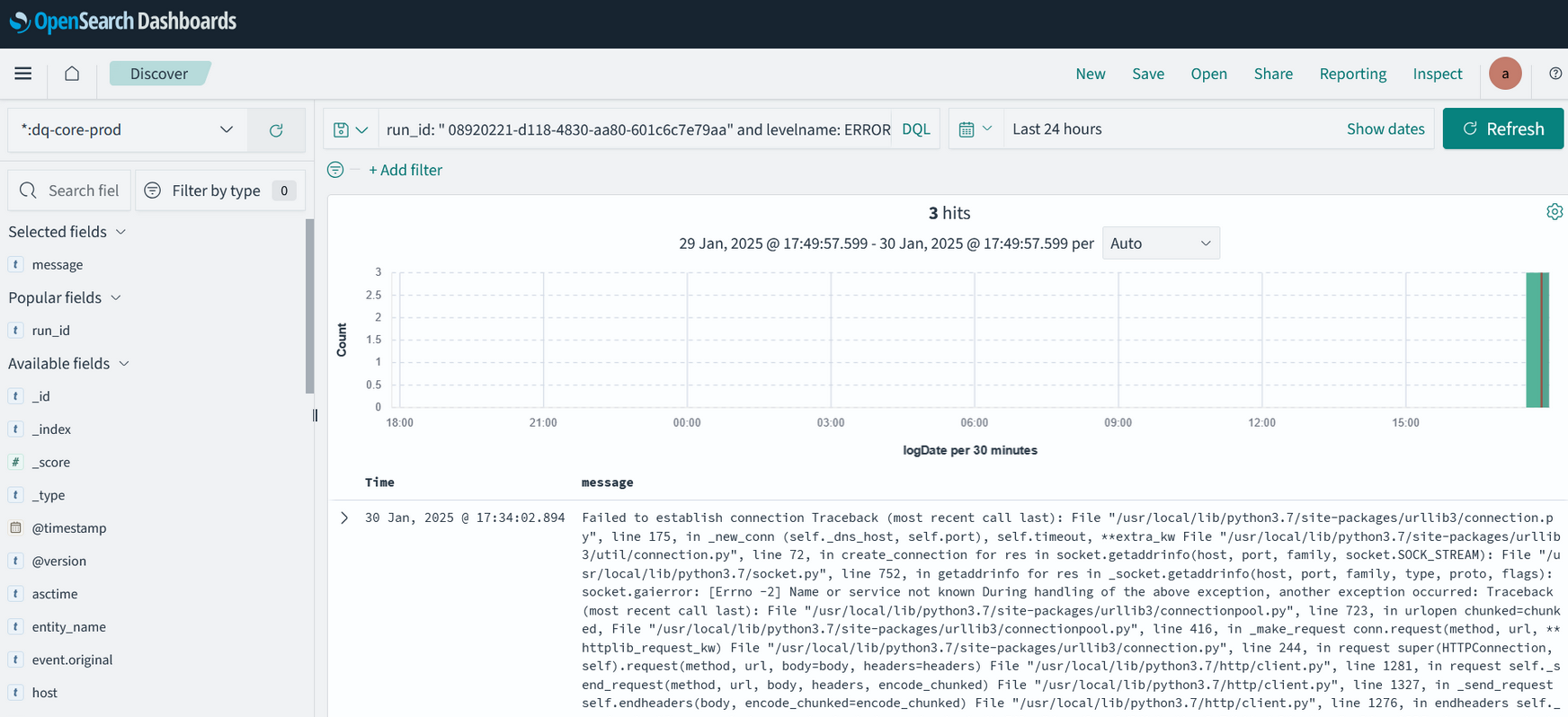
Если DQ запускается из Airflow, эта ссылка с необходимыми фильтрами будет в логе таска DQRunner:

Если вы не используете Airflow для запуска DQ, run_id будет доступен в ответе метода /api/v4/run_group
Виды ошибок
Ошибки spark метрик
1) Ошибка в конфигурации метрики, самый частый кейс, ошибка имеет подобный вид. Решить проблему можно только исправив свою конфигурацию метрики. Текст ошибки содержит исполняемый SQL на источнике.
Развернуть исходный код
Exception on Spark Query: with q1 as ( select count(distinct device) cnt_raw, 1 as rn from raw.table where 1=1 and version_dt i= TO_DATE(CAST(UNIX_TIMESTAMP('2025-01-04', 'yyyy-MM-dd') AS TIMESTAMP)) ), q2 as ( select count(distinct device_key) cnt_dds, 1 as rn from ( select device_key from dds.table_name where reg = 'msk' ) ) select cnt_raw - cnt_dds from q1,q2 where q1.rn = q2.rn
Traceback (most recent call last):
File "/usr/hdp/.../spark2/python/pyspark/sql/utils.py", line 63, in deco
return f(*a, **kw)
File "/usr/hdp/.../spark2/python/lib/py4j-0.10.6-src.zip/py4j/protocol.py", line 320, in get_return_value
format(target_id, ".", name), value)
py4j.protocol.Py4JJavaError: An error occurred while calling o2497.sql.
: org.apache.spark.sql.catalyst.parser.ParseException:
mismatched input 'i' expecting ')'(line 1, pos 137)
== SQL ==
with q1 as ( select count(distinct device) cnt_raw, 1 as rn from raw.table where 1=1 and version_dt i= TO_DATE(CAST(UNIX_TIMESTAMP('2025-11-04', 'yyyy-MM-dd') AS TIMESTAMP)) ), q2 as ( select count(distinct device_key) cnt_dds, 1 as rn from ( select device_key from dds.table_name where reg = 'frs_msk' ) ) select cnt_raw - cnt_dds from q1,q2 where q1.rn = q2.rn
-----------------------------------------------------------------------------------------------------------------------------------------^^^
2) Ошибка в Spark метриках связанная с нехваткой памяти на хосте с воркером DQ. Если вы часто сталкиваетесь с такой ошибкой, попробуйте разнести свои проверки по времени или уменьшите spark.driver.memory, чтобы снизить нагрузку на хост.
Развернуть исходный код
Exception on connection to Spark with spark_conf_parameters {'spark.executor.memory': '16g', 'spark.driver.memory': '16g', 'spark.executor.instances': '4', 'spark.executor.cores': '4', 'spark.yarn.queue': 'core_data_lake_dq', 'spark.app.name': 'DQ_group_name_217488', 'spark.driver.port': 4500, 'spark.fileserver.port': 4600, 'spark.replClassServer.port': 4700, 'spark.blockManager.port': 4800, 'spark.ui.port': 4900, 'spark.driver.bindAddress': '0.0.0.0', 'spark.port.maxRetries': 100, 'spark.sql.orc.filterPushdown': 'true', 'spark.sql.tungsten.enabled': 'true'}: Traceback (most recent call last):
File "/dq-service/core/source_connectors/spark_connection.py", line 54, in create_connection
session = SparkSession.builder.config(conf=conf).enableHiveSupport().getOrCreate()
File "/usr/hdp/.../spark2/python/pyspark/sql/session.py", line 173, in getOrCreate
sc = SparkContext.getOrCreate(sparkConf)
File "/usr/hdp/.../spark2/python/pyspark/context.py", line 340, in getOrCreate
SparkContext(conf=conf or SparkConf())
File "/usr/hdp/.../spark2/python/pyspark/context.py", line 119, in __init__
conf, jsc, profiler_cls)
File "/usr/hdp/.../spark2/python/pyspark/context.py", line 181, in _do_init
self._jsc = jsc or self._initialize_context(self._conf._jconf)
File "/usr/hdp/.../spark2/python/pyspark/context.py", line 279, in _initialize_context
return self._jvm.JavaSparkContext(jconf)
File "/usr/hdp/.../spark2/python/lib/py4j-0.10.6-src.zip/py4j/java_gateway.py", line 1428, in __call__
answer, self._gateway_client, None, self._fqn)
File "/usr/hdp/.../spark2/python/pyspark/sql/utils.py", line 63, in deco
return f(*a, **kw)
File "/usr/hdp/.../spark2/python/lib/py4j-0.10.6-src.zip/py4j/protocol.py", line 320, in get_return_value
format(target_id, ".", name), value)
py4j.protocol.Py4JJavaError: An error occurred while calling None.org.apache.spark.api.java.JavaSparkContext.
: java.lang.OutOfMemoryError: Java heap space
Результат метрики, посчитанной через DQ, незначительно отличается значения, если посчитать напрямую в БД
1) Результат метрики, посчитанной через DQ, незначительно отличается значения, если посчитать напрямую в БД, меньше чем на 1%.
Если в метрике есть фильтр по дате, скорее всего это связано с расхождением в часовых поясах. По-умолчанию, спарк метрики DQ считаются в таймзоне UTC.
Решение - поменять часовой пояс в параметрах группы проверок. См. Переопределение таймзоны в spark сессии
Развернуть исходный код
groups:
- name: my_group
source_parameters:
- source_name_1:
spark_conf_parameters:
spark.sql.session.timeZone: "Europe/Moscow"
spark.yarn.am.extraJavaOptions: "-Dhdp.version=... -Duser.timezone=Europe/Moscow"
spark.driver.extraJavaOptions: "-Dhdp.version=... -Duser.timezone=Europe/Moscow"
Результат проверки = "Отсутствует эталонное значение", метрика не посчиталась
Метрика не посчиталась (нет результата в grafana), у проверки статус 0 (Отсутствует эталонное значение) и в логах нет ошибок.
Скорее всего конфиг составлен таким образом, что DQ не знает, за какую дату запускать метрику.
Это возможно, если метрика не используется в проверках, либо если используется только как reference_metric
Пример такой конфигурации:
Развернуть исходный код
metrics:
...
- name: sum_rows_total
type: custom_sql
check_object: active_projects_information.source_name
check_object_link: metric_result_view
parameters:
sql: "..."
...
compares:
...
- name: percent_delta_count_download_rows_archive_and_count_download_rows_archive_prev
type: percent_delta
metric: count_download_rows_archive
parameters:
min_value: 0
max_value: 100
reference_metric: sum_rows_total
date_reference: PREV
description: "Количество активных записей превышет сумму записей (archive+active) загрузки ранее"
...
groups:
- name: check_socrat_tech_sol
compares:
...
- percent_delta_count_download_rows_archive_and_count_download_rows_archive_prev
...
Здесь метрика sum_rows_total используется в одной проверке, в качестве reference_metric. При этом стоит date_reference = PREV (т.е. мы берем для сравнения значение этой метрики, посчитанное за любую предыдующую дату)
В данном случае мы не можем определить, за какую дату нужно посчитать эту метрику.
Решение: явно добавить метрику в группу:
Развернуть исходный код
...
groups:
- name: check_socrat_tech_sol
compares:
...
- percent_delta_count_download_rows_archive_and_count_download_rows_archive_prev
...
metrics:
- sum_rows_total
Теперь метрика всегда будет вычисляться за дату запуска.
Ошибки на этапе подключения к источнику
Возможные причины:
-
В vault указан неверные креды для подключения к источнику или неверный путь в credentials. См. Конфигурация Source
-
Запрещены подключения к источнику с адреса DQ воркера. Необходимо прописать разрешения на стороне источника.